Week 2 of the Data Jam focused on Working with Data. In order to get data ready for visualizations and analysis, researchers engage in data wrangling. Wrangling your data with various tools allows you to restructure information so that it can be easily understood by people and analyzed by machines. In this workshop, we worked with OpenRefine, a powerful tool for working with data. Watch the recording and read through the workshop notes to learn more about tidying your data, transforming it from one format to another, and extending it with various web services. Here are the key takeaways we covered in the workshop:
1. Data Wrangling Means Many Things
Most people think of the data analysis process like this:
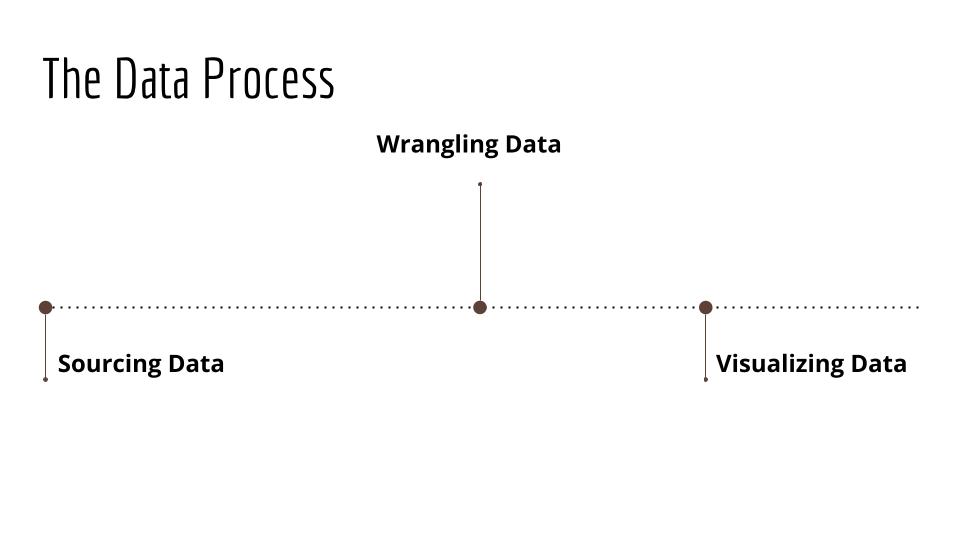
But data wrangling is a term that refers to a number of activities between collecting data and analyzing data, and a much more involved, labor-intensive process.
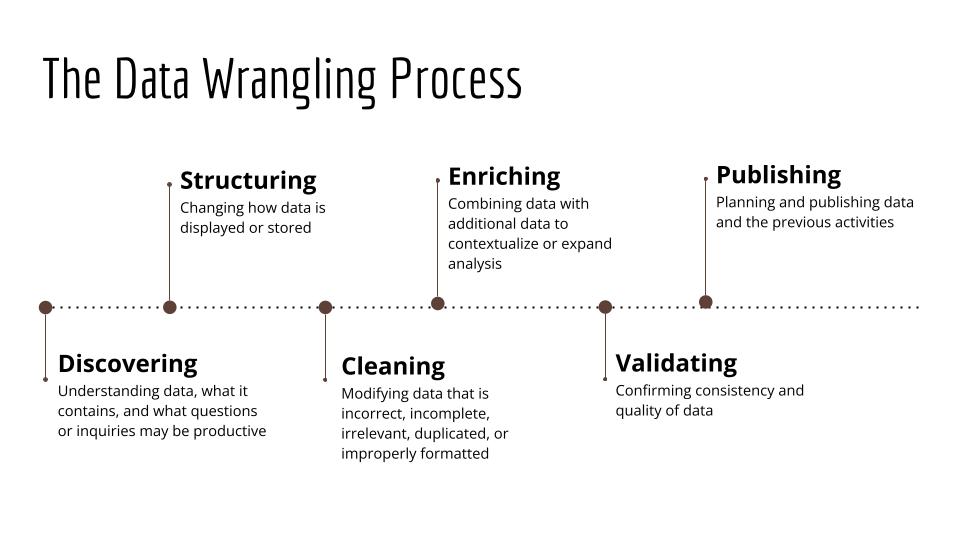
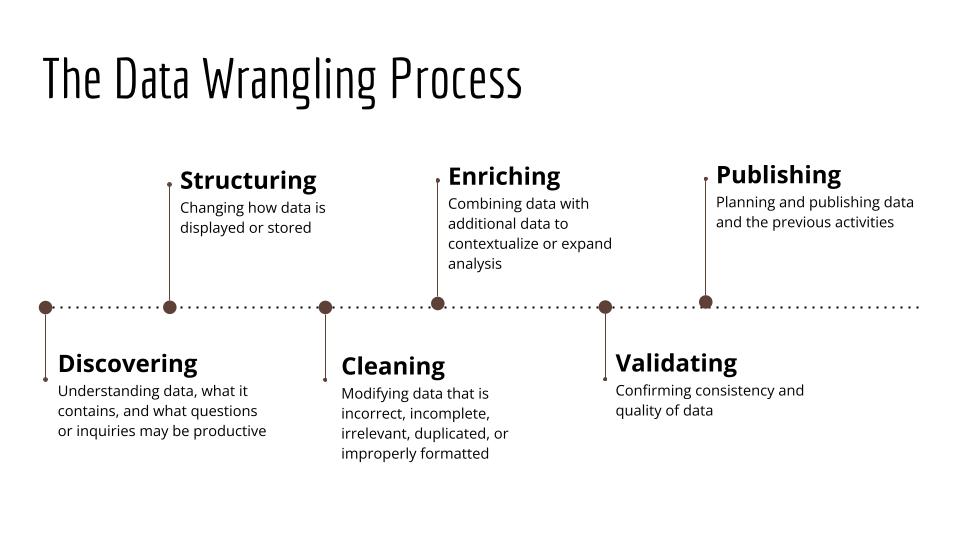
Often, these activities involve:
- discovering (understanding data, what it contains, and what questions or inquiries are productive)
- structuring (changing how data is displayed or stored)
- cleaning (modifying data that is incorrect, incomplete, irrelevant, duplicated, or improperly formatted)
- enriching (combining data with additional data to contextualize or expand analysis)
- validating (confirming consistency and quality of data)
- publishing (planning and publishing data and previous activities)
2. Messy Data vs. Tidy Data
We discussed many different ways data can be considered "messy", such as missing values, inconsistent entry of data, or unclear structure and organizing. Messy data does not mean that this data is bad or unusable. Messy data can be a good thing! But wrangling messy data makes it easier to use, makes it accessible to you and other people, and contextualizes your data for research questions. So we contrasted “messy data” with “tidy data”, which has the following principles:
- Each variable forms a column
- Each observation forms a row
- Each type of observational unit forms a table
If you’re interested in learning more about data cleaning and wrangling, check out:
- Against Cleaning by Katie Rawson and Trevor Muñoz
- Introduction to Tidy Data by Iowa State University Library
- Tidy Data by Hadley Wickham 2.
3. Open Refine Tips
In this workshop, we worked with the Candy Hierarchy data from 2017. Collected by Benjamin R. Cohen and David Ng, these researchers surveyed BoingBoing readers about their emotions towards over 70 different types of candy. We used OpenRefine to clean our dataset to include only respondents between the ages of 18-35 from the United States of America. Cleaning this dataset involved:
- Exploring the dataset and its structure to understand what "messy data" problems were present
- Excluding observations in the dataset to the relevant entries that met our criteria
- Clustering similar variables to ensure consistent spelling within data entry
- Saving and exporting the data cleaning steps and datasets
4. Next Steps
This workshop was based on the Data Carpentry lesson, Data Cleaning with OpenRefine for Ecologists. OpenRefine lists tutorials and resources for you to explore. (I also recommend looking at Thomas Padilla’s Getting Started with Open Refine.) If you’re interested in trying more advanced data cleaning techniques with OpenRefine, this lesson from Programming Historian focuses on fetching and parsing historical data.
OpenRefine isn't the only tool for data wrangling! If you’re already familiar with a particular programming language or software, these guides and tutorials may be helpful.
- Python: The Data Wrangling Workshop (Packt), Python for Data Science – Part 1: Cleaning Data (Cornell University Center for Advanced Computing), Data Cleaning Workshop (The Carpentries)
- R: R Basics: Prepare Data for Modeling and Analysis (Penn Libraries); Data Cleaning, Preparation, and Analysis in R (USCD Libraries)
-
Excel: An Introduction to Data Cleaning with Excel (NUS Libraries); Basic Data Cleaning and Analysis for Data Tables (Duke University Libraries)